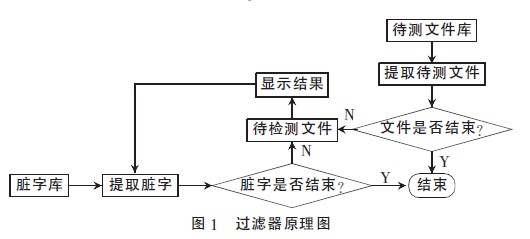
过滤器软件中main函数的主要内容如下:
public static void main(String[] args) {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
String ans=null;
int cnt=0;//字库中关键词个数
int number=0;//脏字出现次数
String filepath="D:\\脏字待测文件库";
//待检测文件路径,此文件夹下可以放若干个待检测的文件
String fileLibrarypath="D:\\脏字典\\file.txt";
//脏字库文件的存放路径
File file = new File(filepath);
try {
//读入用户输入的回车键信息
System.out.println("请按回车键,查看过滤信息:");
String str = null;
str = br.readLine();
if (str != null) {
if (!file.isDirectory()) {
System.out.println("待检测文件路径
不对,请修改路径。");
} else if (file.isDirectory()) {
ans=getcontent(fileLibrarypath);
int k;
StringTokenizer sst=new
StringTokenizer(ans, "|");
k = sst.countTokens();
String[] record = new String[k];
while (sst.hasMoreElements()) {
record[cnt] = sst.nextToken();
cnt++;
}
String[] filelist = file.list();
for (int i = 0, flen = filelist.length; i
< flen; i++){
String temp = filepath +
"\\" + filelist;
number = searchkeyword(record,
cnt, temp);
System.out.println("第"+(i+1) +"文件中脏字出现的次数:" + number);
//字库中关键词个数
}
} else {
//提示用户按回车键
System.out.println("你还没有输入回
车键信息");
}
}
} catch (IOException e) {
e.printStackTrace();
}
//输出查询结果
if (ans != null) {
System.out.println("字库中关键词个数:"+ cnt);//字库中关键词个数
System.out.println("脏字库内容如下:"+ ans);
} else {
System.out.println("没有可以匹配的信息");
//输出脏字库中的内容
}
}
//得到指定路径文件中的内容
private static String getcontent(String filepath) {
String all = "";
File file = new File(filepath);
try {
if (!file.isFile()) {
System.out.println("文件路径不对,请修改路径");
} else {
File readfile = new File(filepath);
BufferedReader br = new BufferedReader(new FileReader(readfile));
String ss = br.readLine();
while (ss != null) {
all = all + ss;
//all中存放读取的文件内容信息
ss = br.readLine();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return all;
}
//在待测文件中匹配脏字出现的次数
private static int searchkeyword(String[] str, int cnt, String filepath){
int number = 0;
String s = "";
s = getcontent(filepath);
for (int i = 0; i < cnt; i++) {
if (s.indexOf(str) > -1) {
number++;
}
}
return number;
}
至此,完成了脏字过滤器软件代码的编写工作,接下来可以进行run操作,即可以得到待测文件库中的待测文件包含脏字次数及出处等相关信息的结果。






 雷达卡
雷达卡
 发表于 2014-10-10 07:53:19
发表于 2014-10-10 07:53:19


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡