|
|
在集群计算系统中,随着系统规模的增大,通信效率是影响整个系统获得高性能的关键因素之一。而随着局域网传输性能的快速提高,Myrinet、Gigabit Ethernet和Infiniband等千兆位网络设备已被广泛使用,当前影响集群节点间通信性能的瓶颈已经从通信硬件的传送开销转移到了通信处理软件的开销上,所以采用优化的通信协议是降低通信成本、提高结点间通信的有效手段。
在当前的集群通信应用中,普遍采用两类通信结构,即核心级通信和用户级通信。但由于它们设计的初衷并非是针对集群通信,所以并不适合当前集群环境的特点。为此,本文通过分析这两类通信结构的特点,提出了以核心级通信为基础,旁路内核中IP层及以上协议层,实现数据链路层直接与MPI通道接口层通信的新机制,并通过实验验证,为传统集群的升级改造提供一种新的无连接、无差错控制,开销小、延时低的通信机制。
1 基于数据链路层的集群通信结构的提出
目前各种通信协议普遍采用两种通信结构,即核心级通信和用户级通信[1]。
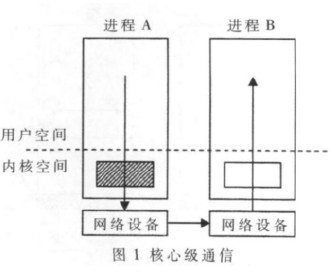
1.1 核心级通信
在核心级通信中,操作系统内核控制着所有消息传递中的发送与接收处理,并且负责它们的缓冲管理和通信协议的实现,设备驱动程序也是通过内核来完成所有的硬件支持与协议软件处理的任务,如图1所示。在通信过程中,系统要经过多次内核态与用户态之间的数据拷贝才能够实现数据的传送。有数据表明[2],一般奔腾处理器的内存拷贝速率平均为70 Mb/s,但是由于操作系统在交换页面时的 I/O 数据传送都是阻塞操作,若出现缺页中断,其时延将会更大,所以频繁的内存拷贝操作的开销将是影响整体性能的瓶颈所在。因此,对于通信效率要求较高的集群计算系统,核心级通信是不适合的。

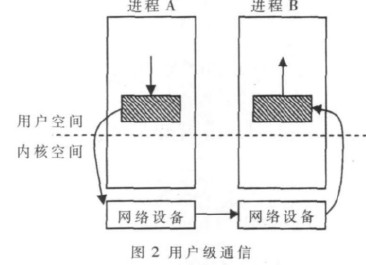
1.2 用户级通信
在用户级通信中,操作系统内核将网络接口控制器NIC(Network Interface Controller)的寄存器和存储器映射到用户地址空间,允许用户进程旁路操作系统内核从直接访问NIC,直接将数据从用户空间发送到网络中进行传输。通信事件处理的触发采用查询方式而不是中断方式,由于旁路操作系统内核,使得整个通信过程省掉了执行系统调用、用户态与核心态之间的数据拷贝及用户与内核的上下文切换等软件上的开销,进而减少对主机CPU资源的占用,缩短通信操作的关键路径,实现通信与计算的重叠。如图2所示[3]。
但是,采用用户级通信协议时,通信过程中的所有操作均在用户空间中进行,当用户程序出错或有恶意用户进行破坏时,系统就很容易被破坏。这是因为系统数据结构中不仅包含本进程(或并行任务)及其相关信息,同时也包含与本进程无关的其他进程(或并行任务)的相关信息。若某一用户(并行任务)出错或失误,都将会影响到其他用户(并行任务)的执行,因而很难保证系统的安全性和可靠性,也无法保证并行任务间的相互独立性。
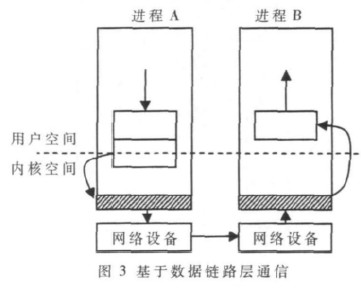
1.3 基于数据链路层通信
为了既能保证系统安全、可靠以及并行任务间相互独立,同时又能降低通信成本,本文提出了一种以核心级通信为基础的基于数据链路层的通信结构,即在操作系统内核(以Linux内核为例)中旁路IP层、INET Socke层和BSD Socket层,使得数据链路层直接与应用程序的通道接口层通信。如图3所示。
图3中阴影部分表示通信关键路径上数据链路层。在该通信结构下,系统在通信的关键路径上将通过内存映射和内存拷贝两种技术实现通信。在发送消息时,系统通过内存映射技术将消息映射到内核中的缓冲区,注册协议标识,并调用数据链路层函数对其进行封包发送;在接收消息时,系统通过数据链路层的MAC地址进行寻址、接收消息,并通过内存拷贝直接将消息传送到用户空间中的应用程序,实现点到点通信。
与用户级通信结构相比,基于数据链路层的通信结构在通信关键路径上只增加了一次内存拷贝的开销。同时,由于保留了数据链路层的通信,进而为系统的安全性、可靠性和并行任务间的独立性提供了保障。此外,该通信结构可以屏蔽系统的硬件信息,使得在应用程序中不再出现与系统通信硬件有关的操作。
与核心级通信结构相比,该通信结构在通信关键路径上减少了协议处理开销、数据拷贝次数和冗余的差错校验,进而提高了系统的通信效率。
2 MPI的通信
MPI(Message Passing Interface)是为基于消息传递的并行程序设计提供一个高效、可扩展、统一的编程环境,是目前主流的并行编程模式,也是分布式并行系统的主要编程环境。在集群环境中MPI并行程序设计中使用的通信模式有阻塞通信、非阻塞通信和组通信,其中阻塞通信和非阻塞通信属于点对点通信,而点对点通信也正是MPI其他通信的基础。
在阻塞通信中,当发送调用函数MPI_Send后即被阻塞,这时,系统会将发送缓冲区中的数据拷贝到系统缓冲区,由系统负责发送消息,而发送者的操作只在拷贝操作完成时结束并返回,不必等待发送完成。但是,如果系统缓冲区不足或消息过长,导致拷贝失败,则发送者将被阻塞,直到消息发送完成为止;同样,当接收者在调用函数MPI_Recv后会被阻塞,直至收到匹配的消息为止[3]。
非阻塞通信主要是通过实现计算与通信的重叠,进而提高整个程序的执行效率。对于非阻塞通信,不必等到通信操作完全结束后才可返回,而是由特定的通信硬件完成通信操作。在通信硬件执行通信操作的同时,处理机可以同时进行计算操作,这样便实现了通信与计算的重叠。发送者调用函数MPI_Isend或接收者调用数MPI_Irecv后,处理机便可执行其他计算任务。在发送(接收)操作开始时,发送者(接收者)使用请求句柄(request handler),MPI通过检查请求来决定发送(接收)操作是否完成,发送者(接收者)通过调用MPI_Test来确定发送(接收)操作是否完成。在发送或接收操作期间,发送者不能更改发送缓冲区中的内容,接收者也不能使用接收缓冲区中的内容。若发送者(接收者)调用函数MPI_Wait,则发送者(接收者)会被阻塞,直到发送(接收)操作完成才能返回[4]。
由此可知,MPI点到点通信在发送缓冲区、接收缓冲区和内核中的系统缓冲区之间进行传递,并由内核发送或接收系统缓冲区中的消息,本文提出的新通信机制就是围绕着系统缓冲区展开的。
3 基于数据链路层的MPI通信机制的设计与实现
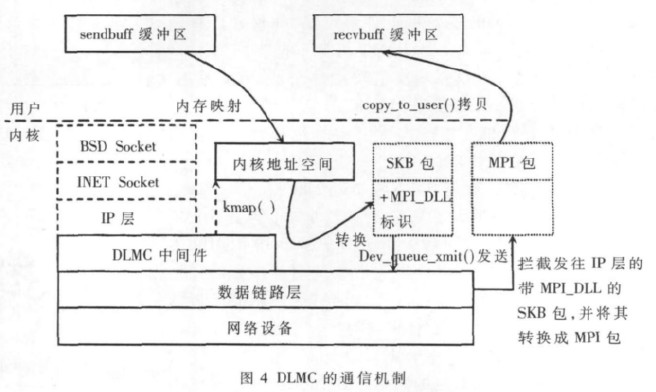
若要实现本文所提出的基于数据链路层的集群通信机制,则需要开发一个中间件DLMC(Data_link Layer MPI Communication)用于提供双方进行通信的底层交换协议、数据包校验、用户空间与内核空间的数据交换和重传机制等。这里需要注意的问题有:
(1)编译方式
对于Linux内核编译分为直接编译进内核和通过模块编译加载进内核。本系统采用模块加载的方式进行编译,其理由是由于系统是在传统Linux网络下进行的修改,只有MPI计算才会用到此中间件,而对于计算之外的部分仍然要依靠传统的TCP/IP。例如计算前期的准备工作,虽然模块加载比直接编译的效率低,但它可以随意动态加载和卸载,这样不仅灵活,而且有利于开发、调试等工作。
(2)用户空间和内核空间之间的数据交换
基于数据链路层的通信进程是在内核空间运行的,而MPI进程是在用户空间进行的,所以需要在用户空间和内核空间进行通信。通过利用Linux内核机制,在用户空间缓存页面以及物理页面之间建立映射关系,将物理内存映射到进程的地址空间,从而达到直接内存访问的目的。
在Linux中,对于高端物理内存(896 MB之后),并没有与内核地址空间建立对应的关系(即虚拟地址=物理地址+PAGE_OFFSET),所以不能使用诸如get_free_pages()函数进行内存分配,而必须使用alloc_pages()来得到struct *page结构,然后将其映射到内核地址空间,但此时映射后的地址并非和物理地址相差PAGE_OFFSET[5]。为实现内存映射技术,其具体使用方法是:使用alloc_pages()在高端存储器区得到struct *page结构,然后调用kmap(struct *page)在内核地址空间PAGE_OFFSET+896M之后的地址空间中建立永久映射。DLMC首先让内核得到用户空间中发送缓冲区的页信息,再将其映射到内核地址空间,并且返回内核虚拟地址,以供DLMC直接将发送缓冲区中的数据传递到数据链路层进行发送,这样就完成了用户地址空间到内核地址空间的映射。
(3)校验与重传机制
由于数据链路层的传输是一种不可靠的网络传输方式,涉及到对传输数据进行数据校验重传等工作。考虑到局域网或者机对机传输的稳定性和可靠性,系统校验方式使用简单的数据校验和,重传机制使用选择重传ARQ方案。当出现差错必须重传时,不必重复传送已经正确到达接收端的数据帧,而只重传出错的数据帧或计时器超时的数据帧,以避免网络资源的浪费。
(4)中断机制
由于本系统改变了TCP/IP的传输机制,所以需要对发出的数据包进行协议标识。系统在初始化阶段,调用内核的dev_add_pack()函数向内核注册了标识为Ox080A的网络数据处理函数。在发送数据包时,系统先通过kmap()函数将MPI的发送缓冲区sendbuff映射到内核映射缓冲区sysbuff,以软中断的方式通知系统,申请分配一个新的SKB来存储sysbuff里的数据包,调用dev_queue_xmit函数,使数据包向下层传递,并清空sysbuff,释放SKB。在接收端需要向内核注册相应的硬件中断处理函数,在接收到数据后唤醒上层的处理函数,并在netif_receive_skb函数(net/core/dev.c)中屏蔽将SKB包向上层传递的语句,改为将SKB里的数据以MPI数据包格式通过copy_to_user函数拷贝到MPI的接收缓冲区recvbuff中,完成数据的接收,其传输过程如图4所示。
4 实验结果与分析
4.1 实验结果和方法
本实验环境是一个4节点的Beowulf集群系统,每个节点包含一个PIV处理器和2 GB内存,操作系统采用Redhat Linux Enterprise 5,并行集群软件为OPEN MPI 1.3。由于条件所限,加之实验规模较小,本实验采用MPI自带的函数MPI_Wtime()来采集MPI计算的开始时间和结束时间,取二者的时间差作为程序的运行时间并对其进行比较和分析。
由于本实验的目的是要测试基于数据链路层的通信机制的可行性,而该通信机制是在TCP/IP协议基础之上构建的,所以本实验对象将以单机系统、基于TCP/IP的MPI集群和基于DLMC的MPI集群作为参照平台进行测试。在实验用例设计上,考虑到两种MPI集群的通信机制中的传输路径不同,所以采用如下两种测试方案:
(1)计算圆周率,主要测试系统的数学函数浮点计算性能,以点对点短消息传输为主;
(2)计算求解三对角方程组,主要测试通信和计算的平衡,以点对点长消息传输为主。
4.2 性能分析
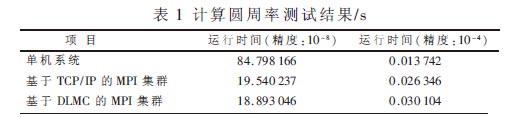
(1)计算圆周率,如表1所示。
测试结果表明,在精度值设为10-8,精确值比较大时,基于TCP/IP的集群(4个进程)的运行时间是19.540 237 s,单机系统(单进程)运行时间是84.798 166 s,并行运算效果明显。在精度值设为10-4,精确值比较小时,基于TCP/IP的集群(4个进程)的运行时间是0.026 346 s,单机系统(单进程)运行时间是0.013 742 s,这是由于并行运算过程中,参与运算的机器需要通过网络传递消息,若计算量规模不大,则在网络传输上花费的时间会比较多,所以反不如单机的运行速度快。从基于DLMC的集群与基于TCP/IP的集群运行结果对比看,在精度值较大时,前者略微快于后者,而在精度值较小时,后者略快于前者,这主要是因为基于TCP/IP的MPI集群在发送和接收的整个过程中,需要2次数据拷贝,即发送缓冲区到内核的拷贝和内核到接收缓冲区的拷贝,同时还有经过各协议层的开销。而基于DLMC的MPI集群在整个的传输过程中,通过使用内存映射,只需要1次数据拷贝,同时旁路IP层及以上各协议层,在这种以短消息传输为主的测试中使得DLMC集群不能发挥其在网络传输上的优势,所以在精度值较大时,二者相差无几;在精度值较小时,反而基于TCP/IP的集群更快一些,这是因为内存映射和内核操作所引入的开销大于1次内存拷贝开销而造成性能的下降。
(2)计算求解三对角方程组,如表2所示。
由测试结果表明,在传输消息较小时,基于DLMC的MPI集群花费的时间略微小于基于TCP/IP的MPI集群,这说明此时基于内存映射和内核调用等操作的开销要高于两次数据拷贝的开销,造成网络延迟略高。但随着传输消息规模的增大,特别是消息大小超过1 MB时,基于内存映射和数据链路层协议的DLMC相对于具有2次内存拷贝的多协议机制的网络延时要小得多,这样使得系统的整体运行时间明显低于传统的TCP/IP集群。
由上分析可知,基于Linux数据链路层的集群通信机制是可行的。在该机制下构建的MPI集群系统完成了无IP条件下的数据传输,并且支持多用户调用,在传输过程中减少了协议开销、和内存拷贝次数,相比于TCP/IP传输有一定提高。但是基于数据链路层协议的特点,该机制只能在局域网范围内运行,所以集群节点数量或规模会受到一定的限制,只能适合中小集群系统的应用。由于实验条件的有限,对集群通信系统未能充分验证,希望在今后的研发工作中能够进一步加强。 |
|






 雷达卡
雷达卡
 发表于 2014-10-10 07:53:19
发表于 2014-10-10 07:53:19


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡